
在ChatGPT诞生之前,谷歌曾经以一己之力掀起了世界人工智能发展的重要浪潮,而响彻全球的是谷歌AlphaGo在2016年的“人机大战”中战胜了韩国围棋棋手李世石。在这背后,支撑AlphaGo“最强大脑”运行的TPU芯片至关重要,而且仍在不断迭代完善。
虽然TPU最初是为内部工作负载而创建,但凭借多项优势,其不仅在谷歌内部得到广泛应用并成为AI支柱,也获得苹果等科技巨头以及多家大模型创业公司的青睐和竞相应用。回头来看,TPU芯片诞生十年之际,逐渐从AI产业边缘走向了舞台中央。然而,由于TPU基础设施主要围绕TensorFlow和JAX构建,谷歌也一定程度面临“技术孤岛”等挑战。

十年“紧跟”人工智能创新
随着机器学习、深度学习算法深入发展,产业界对于高性能、低功耗的专用AI计算芯片需求快速增长。然而,传统的通用CPU以及专攻图形加速、视频渲染等复杂任务GPU无法满足深度学习工作负载的巨大需求,同时存在效率较低、专用运算有限等问题。
谷歌首席科学家Jeff Dean表示,“我们曾做了一些粗略计算,如果每天有数亿人与谷歌进行三分钟的对话需要多少运算能力。当时我们很快意识到,这基本上需要消耗谷歌部署的所有计算能力。换句话说,需要将谷歌数据中心的计算机数量增加一倍来支持这些新功能。”
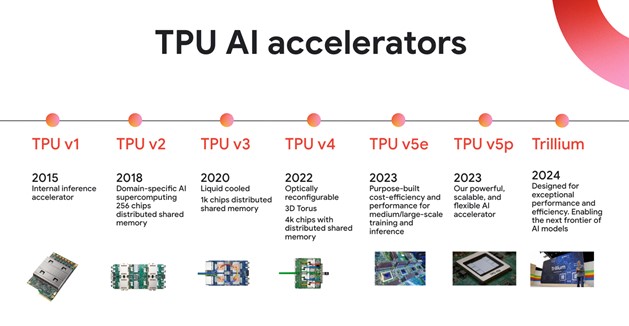
于是,谷歌致力探索更具成本效益、节能的机器学习解决方案,随即启动了TPU项目,并于2015年宣布第一代TPU芯片(TPU v1)在内部上线。TPU 是一种专用集成电路 (ASIC),专为单一特定目的而设计,包括运行构建AI 模型所需的独特矩阵和基于矢量的数学运算。与GPU的矩阵运算有所不同,PU的标志性特征是其矩阵乘法单元(MXU)。
据谷歌副总裁兼工程院士Norm Jouppi 透露,TPU 的出现让足足让谷歌省下了15 个数据中心。至于TPU更具性价比的一个重要原因,是谷歌的软件堆栈垂直集成度比GPU更好。谷歌有专门的工程团队为其构建整个软件堆栈,从模型实现(Vertex Model Garden)到深度学习框架(Keras、JAX和TensorFlow)再到为TPU优化的编译器(XLA)。
在性能方面,TPU v1拥有65536个8-bit MAC(矩阵乘单元),峰值性能为92 TOPS,以及28 MiB的片上内存空间。相比于CPU和GPU,TPU v1在响应时间和能效比上表现出色,能够显著提升神经网络的推理速度。TPU v1 的成功让谷歌意识到:机器学习芯片有广阔的发展前景,因而不断在TPU v1 基础上迭代升级推出性能更先进、效率更高的产品。
例如,TPU v2和TPU v3被设计为服务端AI推理和训练芯片,支持更复杂的AI任务。TPU v4进一步增强了扩展性和灵活性,支持大规模AI计算集群的构建。其中,TPU v2 首次将单颗设计扩展到更大的超算系统,构建了由256 颗TPU芯片构成的TPU Pod。此外,TPU v3 加入了液体冷却技术,TPU v4 引入了光学电路开关,进一步提升了性能和效率。
2023年,鉴于TPU v5芯片遭遇“浮夸”质疑和争议,谷歌直接跳至TPU v5e版本。TPU v5e在架构上进行了调整,采用单TensorCore架构,INT8峰值算力达到393 TFLOPS,超过v4的275 TFLOPS,但BF16峰值算力却只有197 TFLOPS,低于前一代v4的水平。这表明TPU v5e更适用于推理任务,也能映射出谷歌对于AI算力服务市场的战略选择。
在今年5月的I/O开发者大会上,谷歌又发布了第六代TPU Trillium。谷歌云机器学习、系统和云 AI 副总裁兼总经理 Amin Vadhat 表示,Trillium TPU 的峰值计算性能较上一代 TPU v5e提高了 4.7 倍以上,能效则比 TPU v5e 高出 67% 以上,同时高带宽内存容量和带宽是原来的两倍,芯片间互连带宽也增加了一倍,从而满足更先进的 AI 系统需求。

值得一提的是,Trillium能在单个高带宽、低延迟 Pod 中扩展到多达 256 个 TPU。通过利用谷歌在 Pod 级可扩展性、多切片技术和Titanium 智能处理单元方面的进步,用户将能够链接数百个 Trillium TPU 的单独 Pod,以构建 PB 级超级计算机和数据中心网络。
总体来看,TPU技术方案的优势在于拥有更集中的架构设计。与连接到同一板的多个GPU不同,TPU以立方体形式组织,可以进行更快的芯片间通信,并且与博通深度合作大幅提升了通信传输速率。另外,在专用场景和用例需求下,其能够更快速推进产品优化和迭代。但由于TPU基础设施主要围绕TensorFlow和JAX构建,而业界更主流的是使用HuggingFace模型和PyTorch进行创新,谷歌某种程度上也面临“技术孤岛”问题。
获苹果及大量AI创企采用
在应用方面,谷歌TPU项目最初为内部特定需求而创建,并迅速在各个部门得到广泛应用,而且成为AI领域最为成熟和先进的定制芯片之一。据谷歌机器学习硬体系统首席工程师Andy Swing 回忆,他们原本预计只需要制造不到1 万个TPU v1,但最终生产了超过10 万个,应用范围涵盖广告、搜寻、语音、AlphaGo,甚至自动驾驶等多个领域。
随着性能和效率不断进步,TPU芯片逐渐成为谷歌的AI基础设施以及几乎所有产品的 AI 支柱。例如谷歌云平台广泛使用了TPU芯片来支持其AI基础设施,这些芯片被用于加速机器学习模型的训练和推理过程,提供高性能和高效的计算能力。通过谷歌云平台,用户可以访问到基于TPU芯片的虚拟机实例(VM),用于训练和部署自己的机器学习模型。
尽管在云服务上获得了较好用户基础,但谷歌并没有直接向用户销售硬件。业内分析指出,谷歌正在与OpenAI就生成性AI进行激烈竞争,如果销售TPU将直面挑战英伟达,“两头作战”可能不是当前最明智的策略。同时,直接销售硬件涉及高昂开销和复杂的供应链管理,而通过云服务提供TPU可以简化安装、部署和管理过程,减少不确定性和额外开销。
另一方面,谷歌云与英伟达的密切合作也需考量。谷歌不仅在内部使用英伟达GPU,还在其云服务平台上提供基于英伟达GPU的服务,以满足客户对高性能计算和AI应用的需求。
诚然,英伟达的AI芯片已经成为科技巨头的“必争砝码”,但业界也在探寻更多元化的选择。而在内部取得广泛应用同时,谷歌也在试图凭借TPU紧跟人工智能创新向更多客户提供AI服务。Andy Swing表示,“我们采用 TPU 和 pod 设置的地点最符合当前数据中心的能力,但我们正在改变数据中心设计,以更好地满足需求。因此,今天准备的解决方案与明天的解决方案会截然不同,我们正在构建一个充满 TPU 的全球数据中心网络。”
目前,全球已经有多家科技公司使用谷歌的TPU芯片。例如苹果承认采用了谷歌TPU训练其人工智能模型,并称“这种系统使我们能够高效且可扩展地训练AFM模型,包括AFM设备端、AFM服务器和更大的模型。”据苹果方面披露,苹果在8192块TPUv4 芯片上从无到有训练服务器AFM,使用4096的序列长度和4096个序列的批量大小,进行6.3万亿token训练。此外,端侧AFM在2048块谷歌的TPUv5p芯片上进行训练。
另有数据显示,超过 60% 获得融资的生成式 AI 初创公司和近 90% 生成式 AI 独角兽都在使用谷歌Cloud 的 AI 基础设施和 Cloud TPU服务,并广泛应用于社会经济各个领域。
例如Anthropic、Midjourney、Salesforce、Hugging Face和AssemblyAI等知名AI创企在大量使用 Cloud TPU。其中,作为“OpenAI劲敌”,Anthropic使用谷歌Cloud TPU v5e芯片为其大语言模型Claude提供硬件支持,以加速模型的训练和推理过程。此外,许多科研、教育机构等也在使用谷歌TPU芯片来支持其AI相关的研究项目。这些机构可以利用TPU芯片的高性能计算能力来加速实验过程,从而推动前沿科研和教育进展。
值得注意的是,据谷歌官方信息,其最新TPU的运行成本每小时不足2美元,但客户需提前三年预订以确保使用。这或将为大模型企业在瞬息万变的产业中带来较重要挑战。
无论如何,TPU 的十年之路成功证明除了CPU、GPU,业界在追求AI所需算力时还有一条新的道路,同时也成为谷歌几乎所有产品中AI 功能的核心,并支持谷歌DeepMind 先进基础模型乃至整个大模型产业的快速发展。未来,随着AI技术的不断发展和市场持续扩大,可能将有更多企业选择使用谷歌TPU芯片来满足其AI计算需求。但AI硬件也可能会更加专门化,这会让硬件和模型结合更加紧密,从而很难跳出框架寻找新的创新可能性。









